


Preventing Your Data Lake from Becoming a Data Swamp
When considering the expense and effort that goes into maintaining data management systems, it’s no secret as to why our clients are so eager to dive right into a data lake—and in some cases, straight into the reservoir. As we’ve collaborated with our clients through data progression over the past few years, we can say with certainty that as with any technology or process investment, the journey toward a smarter, more connected network takes time. When done correctly, in stages, and with the right partner, companies can achieve their goals and gain a complete understanding of their data, at every stage.
The data management journey can be clearly depicted by the transformation from a pond, to a lake, to a reservoir.

Step One: Data Pond
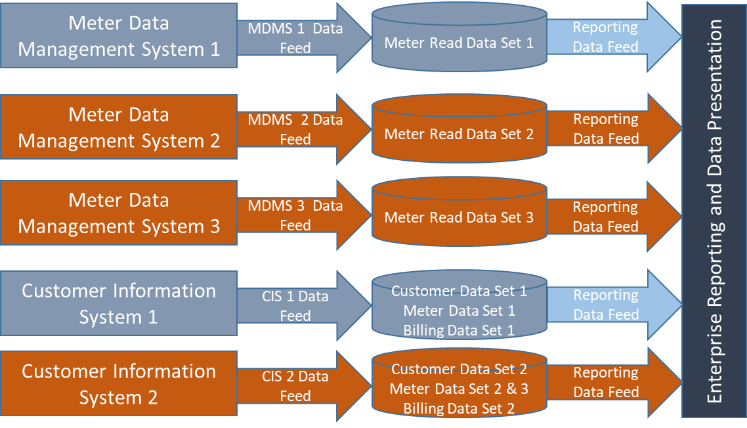
Just as the term ‘pond’ refers to a small body of water, a data pond refers to a small body of data—representing the typical state of business intelligence and data analytics today. Data ponds come with limitations. Say, for example, a utility has three separate meter data management systems (MDM1, MDM2 & MDM3) and two customer information systems (CIS1, CIS2). For this organization, CIS2 is supporting both MDM2 and MDM3. It may sound out of the ordinary, but it’s not uncommon for electric, gas and even water utilities to look around and see this within their architecture. This could be a direct result of mergers and acquisition, attempts at system retirement, or even the relationship between generation and transmission companies and a coop distribution client. It can even apply to outage management systems, geospatial information systems, or distribution and transmission SCADA systems.
Sure, data is copied from existing internal data stores—but it doesn’t push toward a centralized cluster, such as what happens within a data lake, nor does it feature refined data or ensure governance, which is the case within a data reservoir. As such, many companies realize a data pond isn’t sustainable and quickly move toward a centralized consolidation.
Step Two: Data Lake
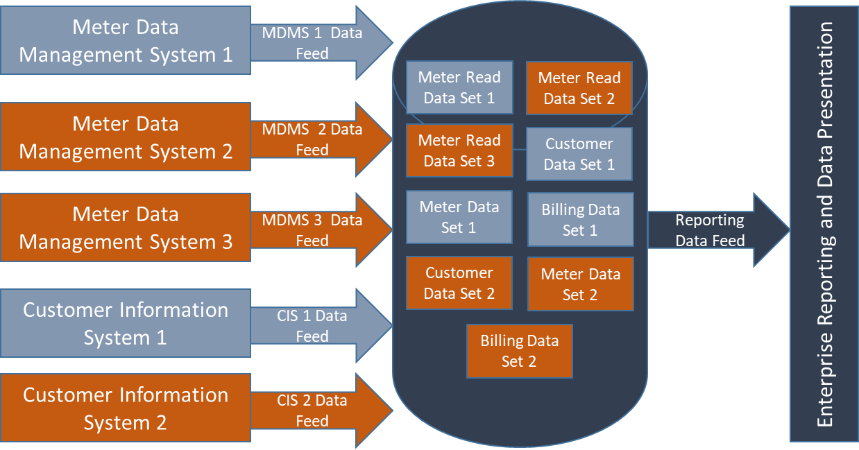
Achieving a common repository calls for a celebration—it means an organization has formed a data lake. However, this celebration is oftentimes cut short because these data lakes don’t always reflect data commonality alongside the common physical location of the data.
In a related scenario, say the data structures of all three MDMs are still retained and must be reconciled every time a new report is needed. Similarly, the two CISs are also retained, which makes generating customer reports, including bills, meters, and meter reads much more extensive and difficult. Even worse, it increases the risk that some data will not be used, causing it to become stagnate for the organization. This lack of data utilization, or even overt data exclusion can then cause the data lake to dry up into a data swamp because when one or more components become retired or replaced, that data will likely be cut off due to the inability to either understand its value or simply obtain it.
We’ve witnessed this exact scenario play out several times, sometimes leading to duplicate system function, or the inability to harvest valuable data because of the challenges associated with format and timing logistics.
Step Three: Data Reservoir
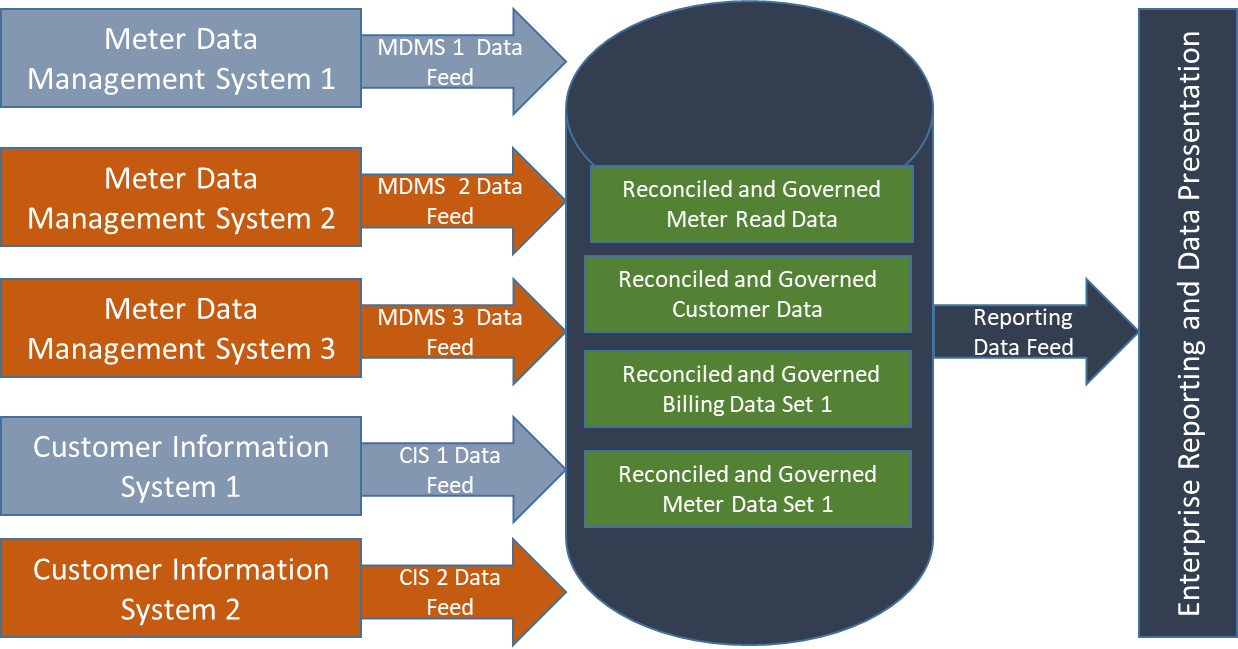
So, what does it take to reach the coveted data reservoir, where there’s a governed compilation of raw and defined data that ensures compliance and safety? One of the key differentiators of a data reservoir is the ability to integrate a common model that reconciles each data object into information objects, allowing the data to persist even after an application is retired. In addition, the data from multiple streams is subjected to governance and auditing to ensure compliance with information object definitions. In this case, all meter-reading feeds are reconciled into a single meter reading structure—regardless of where it comes from. Governance, auditability and compliance combine to make data consumption much more comprehensive, thereby making it possible to preserve relevancy and prevent data stagnation.
In most cases, we join our clients during their transition from data pond to a data lake. And while many tend to think of intelligent data management as a sprint instead of a marathon, it’s not uncommon for hyper-ambition to cause seemingly irreversible damage. Before you can swim with the big fish, you must keep your information from turning into a data swamp.
Check out our framework for more information about the Xtensible Solutions approach to information management.
Related Resources
- Additional Reading:
- Case Study: Long Island Power Authority / PSEG-LI

