


Inmon vs. Kimball: A Review of Differences in Analytical Perspectives
The world of data and analytics is constantly evolving. In its simpler days, typical data organization consisted of some files, application or transactional databases, data warehouses, and reporting data marts. As data sources, volumes, generation speeds and the collection process have grown over the years, today’s computing environment must deal with extremely large data sets – commonly referred to as ‘big data’ – that reveal patterns, trends, and more, on which organizations can base decisions.
Most organizations today have many, if not all, of the components highlighted in the reference architecture conveyed in Figure 1 – applications, systems, and sources, data transfer, enterprise data layer, data services, analytics, and reporting, and advanced data processing.
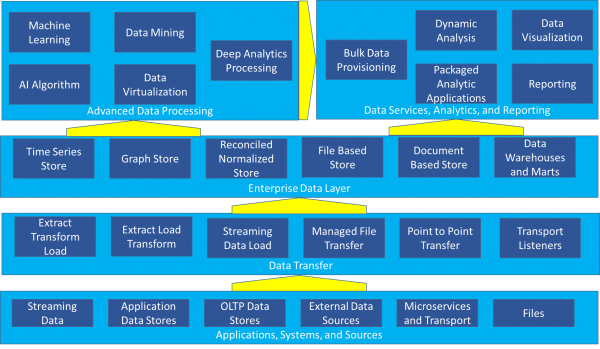
Figure 1 – Complex Reference Architecture
With data warehouse and marts represented as one of 28 possible components, it’s difficult to understand how they fit into the picture at first glance. But most organizations are currently concerned with more than a data warehouse – they must cohesively manage a complex environment like the one depicted in Figure 1.
Kimball and Inmon architectures both offer frameworks to aid in the development of complex reference architecture.
Quick refresher on the two approaches
Before applying the Kimball or Inmon patterns, it’s worth reviewing the differences between the two approaches. Check out the visual representations of each in Figure 21 and Figure 32 .
The work of Kimball and Inmon – the founders of the respective models – challenged each other. While both approaches are predominantly driven by the development cycle of a data model, the models are based on a single-minded focus of either a bottom up, or a top down approach. These tensions played out in the development of the overall data storage and analytics environments.
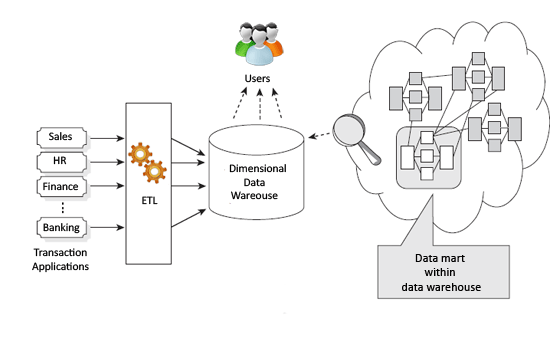
Figure 2 – Visual Kimball
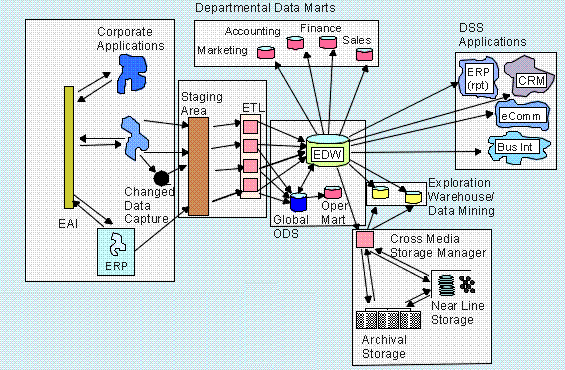
View Figure 3 – Visual Inmon View
The Kimball approach indicates that data warehouses and data marts are driven by business processes and business questions. The obvious danger to this is useful data may not necessarily be categorized or captured since it would not fit within the business process being defined.
The Inmon approach indicates the creation of an enterprise data warehouse with logical models designed for every entity around a topic, such as meter, invoice, and asset. The challenge is while the major topics can represent differentiation, the entities supporting them may represent commonalities which can be lost.
For example, the location of a meter as represented by a service location, the billing address represented in the invoice, and the inventory location or deployment location of an asset can all share common attributes. Even under Inmon, there is a danger that the service location, billing address, asset, inventory location, and asset deployment location could be represented as five different objects, since they are considered to support different verticals in the organization with different data marts.
Both the Inmon and Kimball approaches are driven by the cycle to develop the conceptual data model, then implement the data models in a physicalized form. This cycle can support more agile development approaches, but it will most closely align with a waterfall type of development approach due to the linearity of the research (based on the process or enterprise topic), the development of the conceptual model (based on the data in the process or the enterprise topic), and the development of the physical model.
Taking the next step
An agile process could make it difficult to inject cycles into this type of a development activity. The challenge for every organization will be to take the lessons learned from the Inmon and Kimball approaches, and apply them in a new context.
More details on how to apply the patterns to a complex environment to come in part two of this blog series – stay tuned!
In the meantime, check out our recent post on successfully implementing enterprise information management (EIM).
Footnotes:

